UTF-16
UTF-16 is an encoding scheme for Unicode that represent every code point on 2 or 4 bytes (not on 3 bytes). UTF-16 has a variable length and uses an optional Byte-Order Mark (BOM), but it is recommended to use UTF-16BE (BE stands for Big-Endian byte order), or UTF-16LE (LE stands for Little-Endian byte order). While more details about Big-Endian vs. Little-Endian are available at https://en.wikipedia.org/wiki/Endianness, the following figure reveals how the orders of bytes differ in UTF-16BE (left side) vs. UTF-16LE (right side) for three characters:

Figure 2.5 – UTF-16BE (left side) vs. UTF-16LE (right side)
Since the figure is self-explanatory, let’s move forward. Now, we have to tackle a trickier aspect of UTF-16. We know that in UTF-32, we take the code point and transform it into a 32-bit number and that’s it. But, in UTF-16, we can’t do that every time because we have code points that don’t accommodate 16 bits. This being said, UTF-16 uses the so-called 16-bit code units. It can use 1 or 2 code units per code point. There are three types of code units as follows:
A code point needs a single code unit: these are 16-bit code units (covering U+0000 to U+D7FF, and U+E000 to U+FFFF)
A code point needs 2 code units:
- The first code unit is named high surrogate and it covers 1,024 values (U+D800 to U+DBFF)
- The second code unit is named low surrogate and it covers 1,024 values (U+DC00 to U+DFFF)
A high surrogate followed by a low surrogate is named a surrogate pair. Surrogate pairs are needed to represent the so-called supplementary Unicode characters or characters having the code point larger than 65,535 (0xFFFF).Characters such as the letter A (65) or the Chinese 暗 (26263) have a code point that can be represented via a single code unit. The following figure shows these characters in UTF-16BE:

Figure 2.6 – UTF-16 encoding of A and 暗
This was easy! Now, let’s consider the following figure (encoding of Unicode, Smiling Face with Heart-Shaped Eyes):
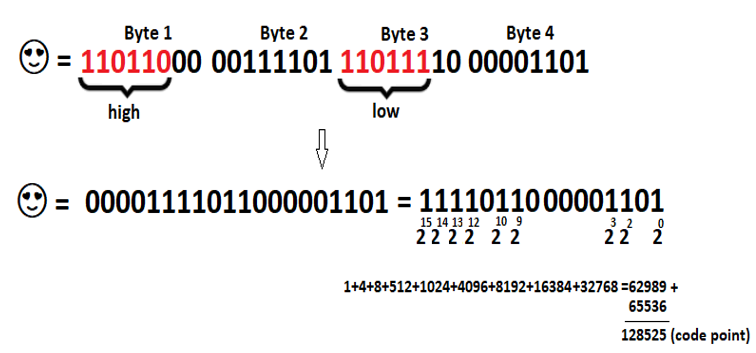
Figure 2.7 – UTF-16 encoding using a surrogate pair
The character from this figure has a code point of 128525 (or, 1 F60D) and is represented on 4 bytes.Check the first byte: the sequence of 6 bits, 110110, identifies a high surrogate.Check the third byte: the sequence of 6 bits, 110111, identifies a low surrogate.These 12 bits (identifying the high and low surrogates) can be dropped and we keep the rest of the 20 bits: 00001111011000001101. We can compute this number as 20 + 22 + 23 + 29 + 210 + 212 + 213 + 214 + 215=1 + 4 + 8 + 512 + 1024 + 4096 + 8192 + 16384 + 32768 = 62989 (or, the hexadecimal, F60D).Finally, we have to compute F60D + 0x10000 = 1 F60D, or in decimal 62989 + 65536 = 128525 (the code point of this Unicode character). We have to add 0x10000 because the characters that use 2 code units (a surrogate pair) are always of form 1 F…Java supports UTF-16, UTF-16BE, and UTF-16LE. Actually, UTF-16 is the native character encoding for Java.